Abstract
A total of 405 respondents evaluated different vignettes (combinations of messages) in four separate but parallel studies, these studies dealing with the breakdown of the healthcare system, the breakdown of the environment, the spread of infectious disease, and terrorist incidents, respectively. The combinations of messages were created by experimental design, allowing statistical deconstruction of the messages into additive models, with each element generating a coefficient showing how the element drives the rating of ‘can’t deal with the situation’. Ten messages were the same across the studies, and were extracted for comparative analysis. Clustering the pattern of these ten coefficients across the four studies, independent of study, suggested three groups; Mind-Set 1: Low basic anxiety but sensitive to specific stressors”; Mind-Set2: “Not particularly discriminating but also possibly anti-religious”; Mind-Set 3:“Overwhelmed and obsessive”. The analysis provides a new approach to understanding how people respond to anxiety-provoking situations, an approach emerging from experimentation rather than from personality-oriented psychological research.
Introduction
As this century proceeds, we are increasingly accustomed to news which increases our anxiety. One need only listen for a half hour of news to hear of unexpected failures of the government to protect its citizens, the fear in the population caused by terrorists who deliberately destroy property and people alike, the rampant diseases which can shut down entire nations as did the Covid-19 virus, and of course those who proclaim that the environment is on its way to making the world inhabitable. One does not need a set of published references for these and many other causes of anxiety. The newspapers will do. But for those who are interested, a sense of the importance of the topics can be seen in Table 1. Table 1 shows the number of ‘hits’ from a search of the four topics, first using Google (up to and including 2022), then Google Scholar (up to and including 2022), and finally Google Scholar only for 2003, the year that the study was run. What is interesting is the focus on the heath system and the environment as most important. Both of these may be said to be future rather than immediate.
Table 1: ‘Hits’ produced by a Google® and Google Scholar® search

The four studies reported here come from an attempt undertaken almost two decades ago, in 2003, to understand the way people think about problem situations. The approach was rooted in background of consumer research, experimental psychology, and statistical design. Rather than asking people to talk about problems, something that is commonly done by qualitative researchers, the focus was to systematically create combinations of messages (vignettes), dealing with issues presumed to drive anxiety (e.g., issues about the destruction of the environment), present these vignettes to respondents, obtain a rating of the vignettes and then deconstruct the ratings into the part-worth contribution of each element as it drives the feeling of ‘can’t deal with it.’
The approach just described above is a process which began as a standard research approach called conjoint analysis [1], and evolved into a variation called Mind Genomics [2,3]. The difference is simple. Both methods, conjoint analysis and Mind Genomics, work with a set of basic ideas or messages, which messages are combined by an underlying procedure known as experimental design [4]. Conjoint Measurement creates one set of combinations, and presents this one set of combinations to many respondents, each respondent evaluating the same combinations but of course in a different order to reduce so-called order bias. One of the benefits of Conjoint Measurement was the fact that it required the researcher to think deeply about the topic, and to create the single set of vignettes, the combinations of messages, in such a way that they made sense.
Some years after the introduction of Conjoint Measurement in its mathematical psychology form, viz., theory, by mathematical psychologists [1] and the popularization by Wharton School professors Paul Green and Jerry Wind [5], it became obvious that one improvement might alleviate the problem of requiring the ‘right guess’ about the vignettes to test. This improvement was to create a basic experimental design, as does Conjoint Measurement, but then permute the design, so each respondent evaluates vignettes created according to the same design structure, but the actual combinations would change [6]. In simple terms, this meant that each respondent would evaluate what turns out to become a totally separate set of combinations.
The experimental design ensures that the elements or messages are statistically independent of each other, allowing for analysis by standard, off-the-shelf methods like OLS (ordinary least squares) regression. The analysis enables the researcher to estimate the contribution of each element in the vignette as a ‘driver’ of the response. Equally important was the realization that no one had to know ‘the answers’ ahead of time, nor spend time identifying the ‘best combinations’ to test. By having each respondent evaluate different permutation of the design, in effect the strategy makes conjoint measurement into an exploratory tool, not a confirmation of one’s best guess. One could go into the study without any knowledge, and still identify ‘what works’.
The foregoing leap, from one design to many designs, is reminiscent of the advances made by the MRI, which takes many ‘pictures’ of a single underlying object, such as body tissue, each picture from a different angle. Afterwards, the computer program recombines these pictures into a three-dimensional representation of the underlying object. In a like manner, the Mind Genomics approach takes many ‘pictures’ of the topic, each picture dictated by the specific combinations in a single permuted design. The result is that for say 100 respondents, one can create a much more detailed, more inclusive picture of the underlying topic, testing the response to many different combinations, rather than testing the response to one combination many times.
The It! Studies and specific ‘Deal With It!’
The development of Mind Genomics software during the late 1990’s and early 2000’s allowed the researcher to set up studies using the Mind Genomics platform. During that time, the author’s business (Moskowitz Jacobs, Inc.) expanded the use of Mind Genomics, moving to studies about the everyday. The ability to set up studies with as many as 36 messages (elements), run the studies using the permuted design, and return in a few hours with the results allowed Mind Genomics to deal with topics on a wider scale. By ‘wider scale’ is meant that that a research project would not be limited to one specific topic, such as the best messages for coffee but might comprise 15-30 related studies, e.g., on foods or beverages [7]. These studies would constitute ‘foundational studies’ of a topic, studies deal with the ordinary facets of daily life, and in their entirety constituting a new form of integrated database about human decision in the ‘everyday’ world.
The four studies reported here come from a of 15 studies called Deal With It!, studies dealing with anxiety-provoking topics. The specific focus in this paper is the response to a set of messages, each of which was the same but in four topics: Environment Degradation, Infectious Disease, Breakdown of the Health Care System and Terrorist acts, respectively. The objective was to understand the degree to which messages about these 15 different anxiety-provoking situations would be perceived as most disturbing. The studies comprise two involving the person in an intimate way (terrorism, spread of infectious disease, particularly relevant in an age of Covid-19), and two involving a breakdown in external structure, (breakdown of the health care system; breakdown of the environment).
The topics were selected from a variety of issues current in the early years of this millennium. The respondents were invited to participate, and selected the one topic which interested them. All 15 topics were available for choice. Figure 1 shows the ‘wall’ of studies available to the respondent. The respondents were invited by a Canadian company, Open Venue Ltd. Which provided respondents from the United States.

Figure 1: The ‘wall’ of the 15 available studies for the ‘Deal With It! Project
Elements (Messages) The Raw Materials for the Study
A hallmark of the It! studies, such as Deal With It! comes from the fact that for the most part the elements or messages in the studies are either parallel or often the same. Table 2 shows the array of 36 elements used in the Terrorism study. The underlying structure of the study comprises four questions, these questions remaining the same across all 15 studies (e.g., Question 1, What Happens), etc.
Table 2: The 36 elements for the Deal With It! study on terrorism, showing the rationale for each element and the actual element
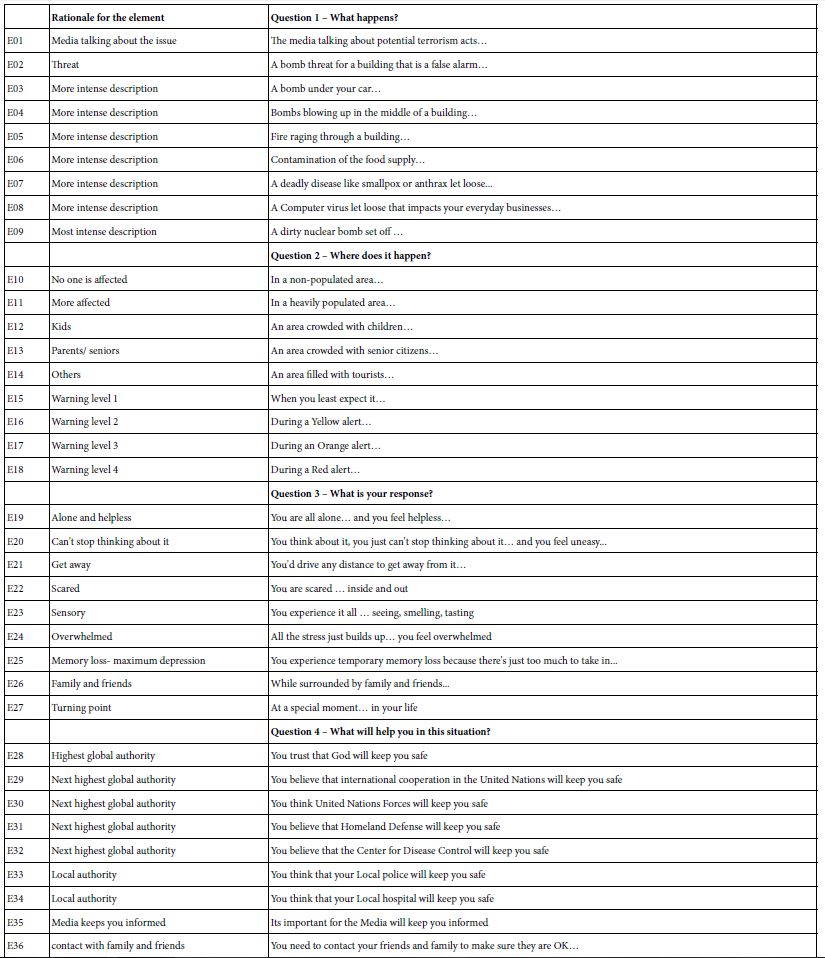
The left side of Table 1 shows the ‘rationale’ for the element. The right side of Table 1 shows the specific text for the answer. Each of the four questions generates nine answers, the elements. The actual questions and answers are left to the researcher, with the Mind Genomics process providing only the design and research template. Across all 15 studies, only Question 3 used the same elements. The three remaining questions comprised answers appropriate for the topic. The analysis in this paper will use only the nine elements or answers generated from Question 3 (elements E19-E27), and the God answer, E28. The texts of these elements were almost identical across the studies.
The Mind Genomics process works by combining elements (answers to questions), according to an underlying experimental design. The combination is put together so the elements appear stacked, one atop the other, without connectives, as shown in Figure 2. The actual experimental design comprises 60 vignettes or combinations with the number of elements in each vignette varying from as few as two to as many as four. The elements appear equally often among the set of 60 vignettes. Finally, each respondent evaluates a unique set of 60 vignettes, different from the combinations evaluated by any other respondent. This is the permuted design [6]. It encourages the researcher to experiment, because the researcher need not select a single set of combinations to test. Rather, one can throw the ideas into the Mind Genomics ‘hopper’, and the strongest elements will emerge.

Figure 2: Example of a four-element vignette and the rating scale
It is important to emphasize here that the vignettes are not ‘polished’, nor do they have to be complete sentences. They can be phrases, presumably written to paint a mental picture. The reality of Mind Genomics experiments is that the respondent does not take the time to read the entire vignette, but rather ‘grazes’ for information. Recent studies during the past five years have incorporated response time, defined as the time elapsed from the presentation of the vignette on the computer and the time that the response is assigned. The various elements are not processed equally rapidly. Responses take the time to read the vignette, as shown by the fact that some elements are characterized by short response times (read quickly), and other elements are characterized by long response times (read slowly; see www.BimiLeap.com).
The instructions at the start of the study, along with the rating scale at the bottom of Figure 2, require the respondent to consider all the messages as belonging to one idea, and to use the scale to rate one’s feeling. The scale is anchored at both ends with 1 representing ‘easy to deal with’, and 9 representing ‘unable to deal with’ this situation.
The 60 vignettes evaluated by each respondent on the 9-point scale were incorporated into a database. Each respondent thus generated 60 rows of data. The first set of columns contain data about the respondent, information such as study, panelist identification number, and information about the panelist obtained by a self-profiling classification. That information is not reported here, simply because it is off-topic, and generally does not correlate with mind-set membership, the topic of this paper.
The second set of 36 columns code the presence/absence of the element. The only information relevant for the analysis at this point is whether the element was absent from the vignette (coded 0) or present in the vignette (coded 1). No metric information about the elements is relevant. The coding is called ‘dummy variable’ coding because of the registration no/yes. The final column was the nine-point rating assigned to the vignette. This nine-point scale was transformed to create a second dependent variable. Ratings of 1-6 denoting ‘can deal well or at least somewhat with the situation described’ were transformed to 0, and a vanishingly small random number added to ensure that the regression modeling would have variation in the dependent variable. Ratings of 7-9, denoting ‘cannot deal with the situation described’ were transformed to 100, and again a vanishingly small random number was added to the transformed variable.
The data matrix described above is configured for straightforward statistical analysis. Recall that each respondent evaluated the precisely correct set of vignettes, combinations of elements, so that all 36 elements were statistically independent of each other. The result is the straightforward estimation of the parameters of the equation or model describing the relation between the presence/absence of each of the 36 elements and the binary transformed rating. The equation is expressed as the simple formula:
Binary Rating (Top 3 → 100) = k0 + k1(E01) + k2(E02) … k36 (E36)
For each respondent, the OLS (ordinary least-squares) regression estimated the contribution of each of the 36 elements to the transformed (binary) rating, as well as estimating the additive constant, k0. The additive constant represents the expected binary value that would be observed in the case of no elements present in the test vignette. Clearly all vignettes comprised a minimum of two and a maximum of four elements, so the additive constant is a computed, purely theoretical correction factor, but one which will allow for interpretation.
For our analysis, we will work with the individual level models, after all 36 coefficients and the additive constant were estimated from the original experiment. For the specific analysis in this paper, we focus only on the additive constant, and the ten common elements across the four studies (E19-E28). These elements have virtually the same wording. The remaining 26 elements are more topic specific. They are discarded from the subsequent analyses presented here, but were necessary for the initial analyses that generated the coefficients E19-E28.
Results – Total Panel
Table 3 shows the models for the four studies, by total panel. Keep in mind that these elements are comparable across the four conditions (H=Health system breaks down I = Infectious disease breaks out; T = Terrorism, E = Environment breaks down).
Table 3: Additive constant and coefficients for the total panel, for four separate studies (H = breakdown of the health care system; I =breakout of an infectious disease; E = breakdown of environment, T = terrorist attack)
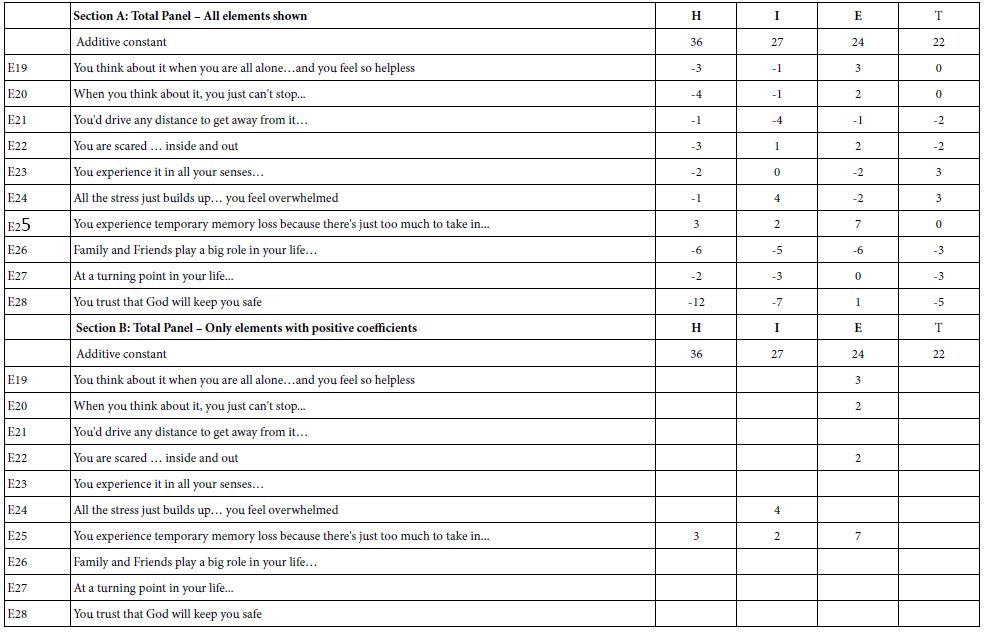
Our first analysis looks at the additive constant. Keep in mind that the high numbers for the additive constant mean that it is hard to cope with the problem, viz., that the respondent simply ‘cannot deal with it.’ The additive constant is the expected inability to ‘deal with it’ in the absence of specific elements. The magnitude of the additive constant suggests that the breakdown of the health-care system is far more ‘anxiety provoking’ than is terrorism or environment breakdown. Anxiety about health can either be manifest in the breakdown of the health-care system (additive constant 36), or an infectious disease (much lower additive constant, 27). Both are higher than the additive constant for environment breakdown (additive constant 24), and for terrorism (additive constant 22), respectively.
Keep in mind that the respondents in this study represent a cross-section of individuals in the United States, most of whom had not been exposed to disease, to environment issues like global warming, or to the problem of terrorism. The results of the study might differ were the same study to be run with today’s population.
Moving beyond the additive constant, Section A of Table 3, we see the coefficients for the total panel, for the 10 ‘common’ elements E19-E28. The positive coefficients give us a sense of the proportion of respondents who would vote 7-9 on this scale if the element were included in the vignette. Looking at the first column, labelled H (pertaining to breakdown in the health care system) we see only one positive coefficient, and indeed a small one, for E25: You experience temporary memory loss because there’s just too much to take in... The coefficient is quite low (+3) but positive meaning that were we to include this element in a vignette, an additional 3% of the respondents would rate the vignette 7-9, viz., unable to deal with the problem. The additive constant for H (breakdown of the health care system) is 36, viz. a baseline without any elements. In turn, incorporating element E25 into the vignette would add 3%, so that the sum would be 39%. This is, we expect 39% of the respondents to say that they cannot deal with the breakdown of the health care system when we present the message: You experience temporary memory loss because there’s just too much to take in…
Table 3 shows a large number of elements which are 0 or negative. The negative values do not mean that these elements ‘reduce anxiety’, but rather mean simply that these elements do not increase anxiety, do not lead the respondent to say ‘I cannot deal with this.’ These elements may do nothing at all, viz., be irrelevant. They are just not anxiety-drivers.
Section B of Table 3 shows the positive coefficients. The convention is to shade all coefficients of values 8 or higher, because from OLS regression this magnitude of coefficient emerges as statistically significant (viz., about two standard errors above 0). The sheer absence of strong performing elements becomes obvious when we look at the preponderance of empty cells, corresponding to of +1 or lower (viz., 1, 0 and negative coefficients, respectively).
Clustering to Create Mind-sets
A hallmark of Mind Genomics is the ability to pull out segments or clusters of respondents with similar patterns of coefficients, doing so by well-accepted statistical procedures. All the individual level coefficients from the four different studies were entered into a common database. Each row comprised information about the respondent, the actual study topic, the additive constant, and the 10 coefficients from the respondent’s own model for the 10 common elements E19-E28.
The clustering procedure [8], k-means clustering, estimates the distance between pairs of respondents based upon the expression: D = (1-Pearson R). The Pearson R, correlation coefficient, shows the strength of the linear relation between two sets of variables. When the relation is perfect, the Pearson R is +1, and the distance, D, is 0. When the relation is perfectly inverse, the Pearson R is -1, and the distance, D, is 2.
The clustering program, k-means, place the respondents first into two mutually exclusive clusters (mind-sets), and then into three mutually exclusive clusters. The objective of clustering is to reduce a set of ‘cases’, here respondents, into a set of groups, such that the groups are parsimonious (fewer groups or mind-sets are better than more groups), and interpretable (the groups should ‘make sense’ in terms of the coefficients which score the highest in the group). The two-cluster solution (viz., mind-sets) was hard to interpret, even though it was the more parsimonious solution. The three-cluster was solution was easier to interpret. Indeed, as the number of clusters increases, the cluster becomes easier to understand, but the results may be less instructive, and solution becomes far less parsimonious. For mind-sets, fewer mind-sets are more instructive than many mind-sets. Fewer mind-sets may be a more general solution, and thus more appropriate as a foundation on which to build deep knowledge.
Table 4 present the coefficients for the three clusters or mind-sets, these mind-sets emerging when all of the data across all respondents in the four studies were combined into one data set. The only data used for the clustering were the coefficients of elements E19 to E28, the ten common elements, across all respondents and across all four studies. In this way it becomes possible to combine the data to find general patterns, and to see how these patterns ‘play out’ in the individual studies once the patterns are established independent of study.
Table 4: Additive constant and coefficients for the three emergent mind-sets, across the four separate studies (H = breakdown of healthcare system; I =breakout of an infectious disease; E = breakdown of environment, T = Terrorist attack)
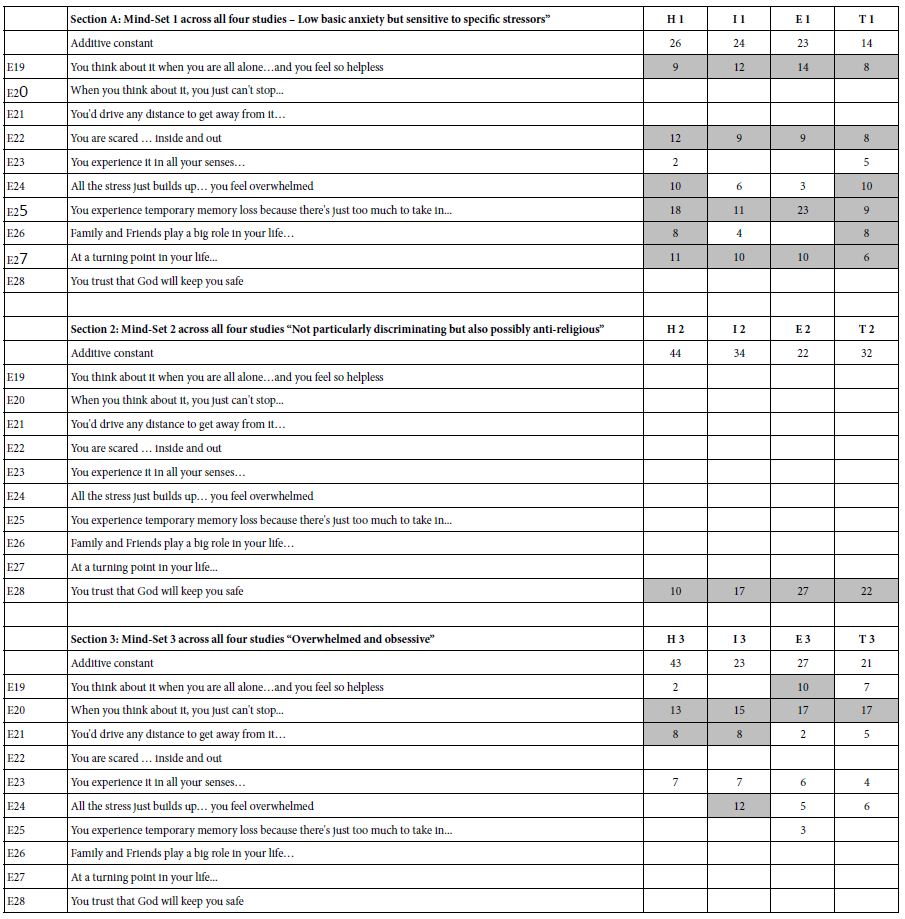
Table 4 shows three sections, one for each mind-set. After the mind-sets were established, each respondent was assigned to one of these mind-sets. The averages of the coefficients in Table 4 were computed for all respondents from the specific mindset, and the specific study. With three mind-sets and with four studies, there are 12 sets of data, each set comprising the 10 averages corresponding to the 10 common elements (E19 – E28). Thus, Section 1 in Table 4 refers to the average coefficients of all respondents in Mind-Set 1, first for the breakdown of the healthcare system (H1), then a breakout of an infectious disease (I1), then the breakdown of the environment (E1), and finally a terrorist attack (T1).
Mind-Set 1
Section A of Table 3 suggests a relatively modest level of anxiety for H (breakdown of health care system), I (breakout of infectious disease disease) and E (breakdown of environment). All three additive constants are in the mid-20’s. In contrast, Mind-Set 1 does not respondent with as much basic anxiety when it comes to terrorism, with an additive constant of 14.
Looking at Mind-Set 1 shows us 20 out of 40 study-element combinations generate strong anxiety, suggesting that Mind-Set 1 comprises individual subject to anxiety. That patterns are similar across the four anxiety-provoking situations.
Mind-Set 1 shows most anxiety to four elements:
E19 You think about it when you are all alone…and you feel so helpless
E22 You are scared … inside and out
E25 You experience temporary memory loss because there’s just too much to take in…
E27 At a turning point in your life…
Mind-Set 1 shows minimal anxiety for three statements:
E20 When you think about it, you just can’t stop…
E21 You’d drive any distance to get away from it…
E28 You trust that God will keep you safe
Mind-Set 2
Section B shows us a group of respondents with substantially different patterns. From the additive constants we get a sense that at a basic level, Mind-Set 2 is quite anxious about the breakdown of the healthcare system. The additive constant is 44, meaning that in the absence of elements, but just knowing that the topic is the breakdown of the health care system 44% of the responses will be 7-9, viz cannot deal with it. Mind-Set 2 is modestly concerned in general about infectious disease (additive constant 34) and terrorism (additive constant 32). Mind-Set 2 is far less concerned about the breakdown of the environment (additive constant 23).
Although Mind-Set 2 seems to be more anxious than Mind-Set 1, at least at a basic level as shown by the additive constants, Mind-Set 2 does not respond strongly nine of the ten messages chosen for analysis. The only exception is the mention of God, which causes strong anxiety in all four studies. It may be that Mind-Set 2 represents those individuals with an anti-religious bent, or at least agnostics, and who do not want to deal with the issue of religion in anxiety-provoking situations.
Mind-Set 3
When we look at the elements which drive the greatest anxiety among respondents in Mind-Set 3, we get a sense of Mind-Set 3 being overwhelmed and obsessive. Element E20 summarizes this mind-set best, and is a strong performer across the four studies: When you think about it, you just can’t stop…
Distribution of Mind-sets across Studies
These data were taken from four studies, each study posing a different problem. Table 5 shows clearly that the three mind-=sets appear approximately equally across the four studies. The distributions are remarkably similar.
Table 5: The distribution of mind-sets 1-3 across the four studies
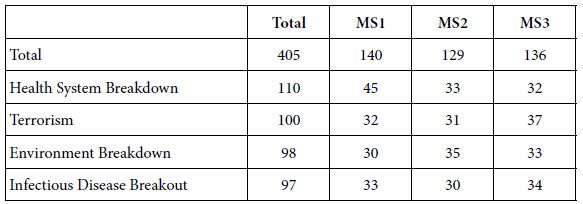
Worthy of note is the fact that the breakdown of the health care system was the study most frequently chosen by the respondents. Recall from Figure 1 that the respondents were presented with the full set of 15 studies. Most of the 15 Deal With It! studies ended up having 100 or so respondents. The 110 respondents for the failure of the health care system is on the high side, suggesting that in 2003 this topic interested the respondent more than did the other studies, like terrorism, which ended up with 100 respondents.
Discussion and Conclusions
The notion of emotions and anxiety has long been a topic of interest for researchers as well as clinicians. Clinicians working with people suffering from anxiety understand the nuances of anxiety, and can adjust their response to their clients in accordance with the nature of the anxiety presented by the individual client. It was this recognition which motivated the original studies two decades ago. The desire was to marry the power of Mind Genomics experimentation to situations that would be considered anxiety provoking.
At that time there were some studies emerging from experimental psychology, dealing with anxiety. These studies, however,, these studies did not combine the power of language, experimentation, and human experience to understand the nuances of anxiety. Anxiety was at best either a general topic in the area of clinical, school, or performance psychology [9-11]. The focus in these clinical studies was the nature of anxiety, the way people become anxious, the approaches to reduce anxiety, and for the world of physiology, the neurological underpinnings of anxiety. There are papers dealing with about anxiety as a response to the everyday stressors of life (e.g., [12-15], as well as the standard clinically-oriented papers focusing on the psychological causes and behavioral manifestations of anxiety (e.g., [16]).
In contrast to the psychology underpinnings of anxiety, the It! studies had started out after success with the approach studying foods and beverages [17]. With food and drink, three overwhelmingly clear mind-sets emerged in topic study after topic study (viz., a study on potato chips versus a study on beer). These three mind-sets were the Elaborates, Imaginers, and Traditionals, respectively. The emergence of these basic mind-sets was clear, perhaps because food is tangible, and simple to understand.
As the Mind Genomics system became more familiar, and as results began to accumulate, it was clear that the approach of giving messages need not be limited to studies of products themselves, but could be expanded to situations such as ‘buying in a store’ (Buy It!), ‘insurance’ (Protect It!), and afterwards to the topic of anxiety in daily life (Deal with It!, from which these data are taken). When the Deal With It! studies were first run, the objective was to discover whether or not anxiety as expressed when one reads about everyday stressors could be deconstructed into different major mind-sets, as was the case with food [18].
The data as reported here confirms that it both straightforward and enlightening to study different topics with Mind Genomics, with some but not all of the elements created to be appropriate for the specific topic. As long as the researcher can incorporate the same elements in different studies, and use the same rating scale, it becomes straightforward to compare similar test stimuli across conditions. In the present study the comparison is made with th 10 common elements, across four studies run in the same way, but dealing with a different cause of anxiety.
Given the simplicity of the approach, now templated albeit with 16 elements rather than with 36 elements (see www.BimiLeap.com), it is becoming increasingly possible to ‘map’ the nature of anxiety across countries, times, and situations, as well as identify people by their individual patterns. Whether there are two, three or more mind-sets in anxiety is not the issue. That question can be answered by ongoing research, studies that are easy, fast, and inexpensive to implement. The real topic is whether from these studies we can begin to create a new science of society, one created from the inside out, from the mind of the person outwards. This approach, almost an inner psychophysics of mind in society, if done expeditiously and without overthinking, might well become a major direction for social science in the coming decades. A beginning effort in that direction is represented by recently published books on Mind Genomics applied to the law [19], and Mind Genomics applied to societal issues in the United States [20].
Acknowledgment
The author would like to acknowledge the cooperation of It! Ventures, LLC which sponsored the studies, especially, and the efforts of the late Hollis Ashman of the Understanding and Insight Group, Inc.
References
- Luce RD, Tukey JW (1964) Simultaneous conjoint measurement: A new type of fundamental measurement. Journal of Mathematical Psychology 1: 1-27.
- Moskowitz HR (2012) ‘Mind genomics’: The experimental, inductive science of the ordinary, and its application to aspects of food and feeding. Physiology & Behavior 107: 606-613. [crossref]
- Moskowitz HR, Gofman A, Beckley J, Ashman H (2006) Founding a new science: Mind Genomics. Journal of Sensory Studies 21: 266-307.
- Mead R (1990) The Design of Experiments: Statistical Principles for Practical Applications. Cambridge University Press.
- Green PE, Wind Y, Carmone FJ (1972) Subjective evaluation models and conjoint measurement. Behavioral Science 17: 288-299.
- Gofman A, Moskowitz H (2010) Isomorphic permuted experimental designs and their application in conjoint analysis. Journal of Sensory Studies 25: 127-145.
- Moskowitz HR, Gofman A (2007) Selling Blue Elephants: How to Make Great Products that People Want Before They Even Know They Want Them. Pearson Education.
- Likas A, Vlassis N, Verbeek JJ (2003) The global k-means clustering algorithm. Pattern recognition 36: 451-461.
- Cattell RB, Scheier IH (1958) The nature of anxiety: A review of thirteen multivariate analyses comprising 814 variables. Psychological Reports 4: 351-388.
- Lader MH (1972) The nature of anxiety. The British Journal of Psychiatry 121: 481-491.
- Eysenck MW (2013) Anxiety: The cognitive perspective. Psychology Press.
- Beattie J (2003) Environmental anxiety in New Zealand, 1840-1941: Climate change, soil erosion, sand drift, flooding and forest conservation. Environment and History 9: 379-392.
- Bosco SM, Harvey D (2003) Effects of terror attacks on employment plans and anxiety levels of college students. College Student Journal 37: 438-447.
- King NB (2003) The influence of anxiety: September 11, bioterrorism, and American public health. Journal of the History of Medicine and Allied Sciences 58: 433-441.
- Sunstein CR (2003) Terrorism and probability neglect. Journal of Risk and Uncertainty 26: 121-136.
- Berde C, Wolfe J (2003) Pain, anxiety, distress, and suffering: interrelated, but not interchangeable. The Journal of Pediatrics 142: 361-363. [crossref]
- Moskowitz HR, Beckley J (2005) Large scale concept-response databases for food and drink using conjoint analysis, segmentation, and databasing. The Handbook of Food Science, Technology, and Engineering, 2.
- Gofman A (2009) Extending Psychophysics Methods to Evaluating Potential Social Anxiety Factors. Medicine 346: 1337-1342.
- Moskowitz HR, Wren J, Papajorgji P (2020) Mind Genomics and the Law. Lambert Academic Publishers, Germany.
- Moskowitz H, Kover A, Papajorgji P (2022) Applying Mind Genomics to Social Sciences. IGI Global.