Abstract
Background: Tricothecene mycotoxins such as Deoxynivalenol (DON) and its metabolite deepoxy-DON (DOM-1), can alter major intracellular signaling pathways within theca cells that can perturb normal folliculogenesis in the ovary resulting in infertility in dairy cows. They function through the activation of a specific tyrosine kinase receptor that transduces the signal by activating several intracellular signaling pathways.
Materials and Methods: In our experimental study, the bovine ovarian theca cells were collected from adult cows during the follicular phase of the estrous cycle and were cultured at a density of 500 000 viable cells for 5 days. The cells were treated on day 5 of the culture with 1 ng/mL DON and DOM-1 for 30 minutes and used mass spectrometry (MS) approach to identify changes in the proteome profile of the cells.
Results: We identified approximately 93 peptides were phosphorylated, and 254 peptides were dephosphorylated in response to DON and DOM-1 compared with non-treated control cells. Gene ontology (GO) analysis indicated that the abundance of proteins associated with cell proliferation such as MAPK3/1, MAPK14, GNGT1, EDN1 and YWHAB were up-regulated in the DON and DOM-1 compared to the control group.
Conclusion: This study reports for the first time that DON and DOM-1 at sub-toxic level can activate major mitogen-induced proliferative molecules within theca cells that can stimulate tumorigenesis in the ovary.
Keywords
Bovine ovary, Deepoxy-deoxynivalenol, Deoxynivalenol, Proteome, Theca cells
Introduction
Fertility in dairy cows has decreased worldwide over the last several decades [1]. Female reproductive function can be affected by numerous environmental factors, including toxins of plant or fungi-associated mycotoxins [2]. Mycotoxins are toxic metabolites produced by some mold species such as Fusarium, Aspergillus and Penicillium that can contaminate food at all stages of the feed chain [3]. Among mycotoxins, deoxynivalenol (DON) produced by Fusarium species, is commonly detected in cereal crops, including wheat, barley and maize and is the most abundant trichothecenes in animal food [4]. DON (vomitoxin) causes acute and chronic toxicity in different internal organs of humans and animals [5] and exerts its toxicity mainly through binding to the ribosome, inhibiting protein and nucleic acid synthesis that triggers ribotoxic stress response, activation of MAPKs and their downstream signaling pathways [6]. According to the studies on human and mice, bacteria are able to de-epoxidize or epimerize DON, to deepoxy-deoxynivalenol (DOM-1) or 3-epi-deoxynivalenol (3-epi-DON), respectively which are substantially less toxic than DON. They only form two hydrogen bonds and subsequently altered their interaction with the ribosome and do not activate MAPKs [7]. In ruminant species, ruminal microorganisms are able to detoxify DON by converting it to the DOM-1, however despite this biochemical degradation DON-associated subclinical health problems are still occurring in dairy cows [8]. Nevertheless, the impact of DON and DOM-1 on reproductive system has not been well explored. This study for the first time investigated the effect of mycotoxins on ovarian theca cell function. Although theca cells consist major part of the follicular structure, their role in follicular function has not well studied, however there is no doubt about their contribution in coordinating some signaling networks between pituitary gland, oocyte, granulosa cells and endothelial cells within the ovary. They have receptor for LH and produce androgens that can be converted to estrogens by granulosa cells, thus any alteration in the normal physiologic function of these cells can have significant impact on follicular development and ovulation process resulting in infertility [9]. Thus, the objective of the present study was to shed light on the mechanism of action of DON and DOM-1 in bovine theca cells by their effects in the phospho-proteome alterations. Therefore, we used mass spectrometry approach, to evaluate the intracellular pathways of bovine theca cells activated following exposure to the sub-toxic doses of mycotoxins-DON and DOM-1.
Materials and Methods
Cell Culture
Our study was experimental. All materials were obtained from Life Technologies Inc. (Thermo Fisher Scientific, Burlington, ON, Canada) unless otherwise stated. Bovine theca cells were cultured in serum-free conditions that maintain testosterone, progesterone secretion and responsiveness to LH [10]. Bovine ovaries were obtained at the slaughterhouse from adult cows, independently of the stage of the estrous cycle, and transported to the laboratory at 30 ºC in phosphate-buffered saline (PBS) containing penicillin (100 IU) and streptomycin (100 µg/mL) [11]. Follicles (4–6 mm diameter) were bisected within the ovarian stroma, gently scraped to remove granulosa cells, and the theca ‘shells’ were peeled from the ovarian stroma with forceps. Pooled theca layers were incubated with collagenase (type IV, 1 mg/mL; Sigma-Aldrich, Oakville, ON, Canada) and trypsin inhibitor (100 ng/mL; Sigma) in a water bath at 37 ºC for 45 min with agitation every 10 min. The resulting supernatant was filtered through a 150 mesh steel sieve (Sigma-Aldrich), centrifuged (800 g for 10 min) and the pellet resuspended in PBS before being subjected to an osmotic shock treatment to remove red blood cells [12]. After washing, cells were resuspended in culture medium McCoy’s 5A modified medium supplemented with 100 IU/mL penicillin, 100 µg/mL streptomycin, 1 µg/mL fungizone, 10 ng/mL bovine insulin, 2 mM L-glutamine, 10 mM HEPES, 5 µg/mL apotransferrin, 5 ng/mL sodium selenite, and 0.1 % BSA (all purchased from Sigma-Aldrich) and LH [13]. Cell viability was assessed by trypan blue dye exclusion, seeded into 24-well tissue plates (Sarstedt Inc., Newton, NC, USA) at a density of 500,000 viable cells in 1 mL, and cultured at 37 ºC in 5 % CO2, 95 % air for a total of 6 days with medium changes every 2 days.
Experimental Treatments In Vitro
Certified Biopure Standard grade DON and DOM-1 in acetonitrile were purchased from Romer Labs (Tullin, Austria), and were reconstituted in methanol for cell culture studies. To assess the effect of DON and of DOM-1 on intracellular pathway activation, cells were treated on day 5 of culture with 1 ng/mL DON and DOM-1 for 30 minutes, and cells were recovered in RIPA buffer to measure the phosphorylation status of key protein kinases. Control cell group was run into two separate groups including solvent (acetonitrile) and the other without solvent and DON or DOM-1. All experiments were run on three separate replicates composed of pools of theca cells obtained from the slaughterhouse in different occasion.
Phosphopeptide Extraction
Proteins (50 µg) were isolated of cells by precipitation with 50 µL of ethanol, centrifuged at 9,000 g for 10 min, and the protein pellet was dried for 20 min in a vacuum centrifuge set at 60 ˚C. The protein pellet was dissolved in 50 µL of 100 mM ammonium bicarbonate (pH 8.5) and the solution was sonicated for 30 min at maximum intensity to improve protein dissolution [14]. The proteins were denatured by heating at 120 ˚C for 10 min, cooled for 15 min at room temperature, and proteins were reduced with 20 mM DTT at 60 ˚C for 60 min. Then proteins were alkylated with 40 mM IAA (Iodoacetamide) at room temperature for 30 min. One µg of proteomic-grade trypsin (i.e. ratio 1:50) was added and the mixture incubated at 40 ˚C for 24 h. The protein digestion was quenched by adding 50 µL of a 1% TFA solution (trifluoroacetic acid), followed by centrifugation at 9,000 g for 10 min, and supernatants were transferred into injection vials for analysis [15]. Phosphopeptide enrichment was performed with the Titansphere ᵀᴹPhos-Tio Kit, which is based on titanium dioxide (TiO2) enrichment. After equilibration of the TiO2 matrix by sequencial washing with Buffer A (2% TFA in acetonitrile solution 1:4 vol:vol) and Buffer B (provided in the kit),then peptide sample (15 µL) was diluted in 50 µL Buffer B and centrifuged through the TiO2 three times at 1000 g for 10 min to adsorb phosphopeptides to the matrix. Non-phosphorylated peptides were sequential washed off the matrix by Buffer B, Buffer A, and phosphopeptides which were eluted 5% ammonium hydroxide followed by 5% pyrrolidine solution [16].
Mass Spectrometry
A Thermo Scientific Q-Exactive Orbitrap Mass Spectrometer (San Jose, CA, USA) was interfaced with a Thermo Scientific UltiMate 3000 Rapid Separation UHPLC system using a pneumatic assisted heated electrospray ion source. The chromatography was achieved using a gradient mobile phase along with a C8 column (Thermo Biobasic 100 × 1 mm) with a particle size of 5 μm. The initial mobile phase condition consisted of acetonitrile and water (both fortified with 0.1% of formic acid) at a ratio of 5:95. From 0 to 1 min, the ratio was maintained at 5:95. From 2 to 62 min, a linear gradient was applied up to a ratio of 50:50 and maintained for 3 min. The mobile phase composition ratio was reverted at the initial conditions and the column was allowed to re-equilibrate for 15 minutes for a total run time of 80 minutes. The flow rate was fixed at 75 µL/min and 2 µL of samples were injected. MS detection was performed in positive ion mode and operating in scan mode at high-resolution, and accurate-mass (HRAM). The default scan range was set to m/z 400-1500. Data was acquired at a resolving power of 140,000 FWHM (or full width at half maximum) using automatic gain control target of 3.0×106 and maximum ion injection time of 200 msec [17].
Bioinformatic Analyses
Database searching was performed on Proteome Discoverer software (version 1.4) with Uniprot bovine protein database (extracted FASTA file). Mass tolerance of precursor and fragment were set at 5 ppm and 10 ppm, respectively. Phosphorylation at Y and T amino acids was set as a variable post-translational modification. Quantification was based on MS1 ion intensity and peptide identification was based on precursor ion (MS1) and at least three characteristic (MS2). Data from all experimental groups were analyzed using SIEVE (Thermo Scientific, San Jose Ca), a label-free differential expression software that aligns the MS spectra over time from different data sets and then determines structures in the data (m/z and retention time pairs) that differ. The following parameters were set to align the retention time and generate the frames needed for abundance calculations. Alignment Parameters; Alignment Bypass = False, Correlation Bin Width = 1, RT Limits for Alignment = True, Tile size = 300, Max RT Shift = 0.2, m/z Min = 400, m/z Max = 1,500, Frame time Width (min) = 2.5 min, Frame m/z width = 10 ppm, Retention Time Start = 2.0 min, Retention Time Stop = 65 min, Peak Intensity threshold = 100,000.
Statistical Analysis
Significance was calculated within SIEVE using a student’s t test. A p-value of less than 0.05 was considered statistically significant. A fold change threshold (> 2 for up-regulation or < 2 for down-regulation) were used to assess differentially expressed peptides [18]. Identification of gene ontology (GO) annotation terms and analysis of networks between differentially phosphorylated proteins were performed based on the biological process [19] and molecular function by Reactome [20] and illustrated by STRING [21] protein interaction software.
Results
A total of 93 peptides were phosphorylated (Table S2), while 254 peptides were dephosphorylated (Table S3) in response to DON and DOM-1 compared with non-treated control cells. There was not different significantly between DON and DOM-1 group.
Differential Regulation of Proteins Expression in DON
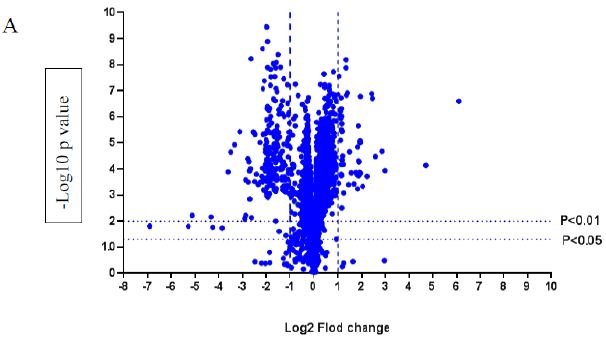
A volcano plot of phosphopeptides detected after treatment with DON is presented in Figure 1A. Identified proteins with significantly increased and decreased phosphorylation status are illustrated in Figure 1B. In this graph the values greater than +1 and lower than -1 represent more than 2-fold increase or decrease in phosphorylation, respectively (P < 0.05).
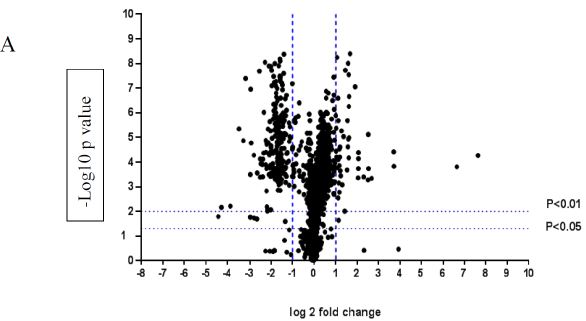
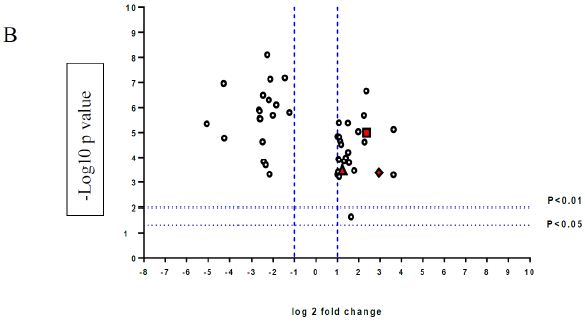
Figure 1: A volcano graph illustrating distribution of different upregulated and downregulated fragment peptides in bovine theca cells exposed to DON. Fold change threshold >2 (log2=1) for up-regulation or <2 for down-regulation) were used to assess differentially expressed proteins. The Y axes indicate significance levels. Graph A illustrates all the phosphorylated proteins inside the cells. Identified proteins with significantly increased and decreased phosphorylation status are illustrated in graph B. The core MAPKs 1, 13 and 14 are shown as red triangles, diamonds and squares, respectively.
Differential Regulation of the Phosphopeptides Expression in DOM-1
A volcano plot of phosphopeptides detected after treatment with DOM-1 is presented in Figure 2A. Identified proteins with significantly increased and decreased phosphorylation status are illustrated in Figure 2B. In this graph the values greater than +1 and lower than -1 represent more than 2-fold increase or decrease in phosphorylation, respectively (P < 0.05).
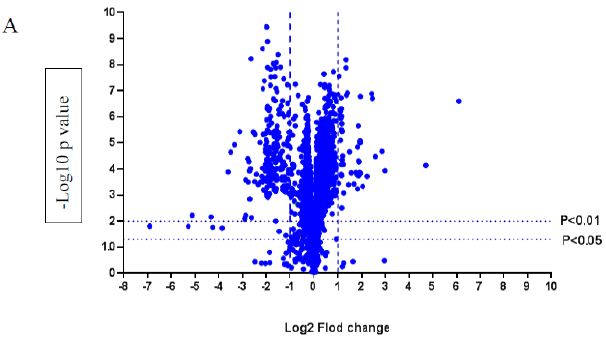
Figure 2: A volcano graph illustrating distribution of different upregulated and downregulated fragment peptides in bovine theca cells exposed to DOM-1. Fold change threshold >2 (log2=1) for up-regulation or <2 for down-regulation) were used to assess differentially expressed proteins. The Y axes indicate significance levels. Graph A illustrates all the phosphorylated proteins inside the cells. Identified proteins with significantly increased and decreased phosphorylation status are illustrated in graph B. The core MAPKs 1, 13 and 14 are shown as red triangles, diamonds and squares, respectively.
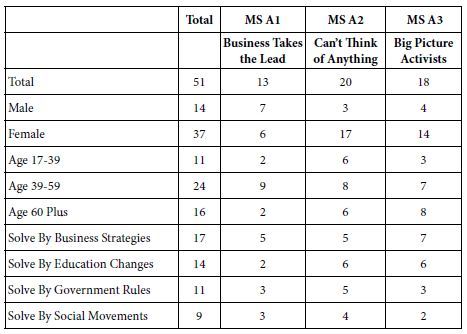
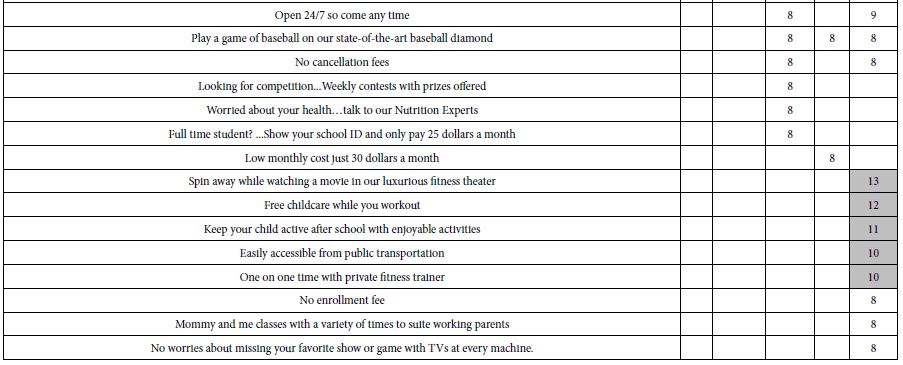
Biological Functions Associated with Mycotoxin Exposure
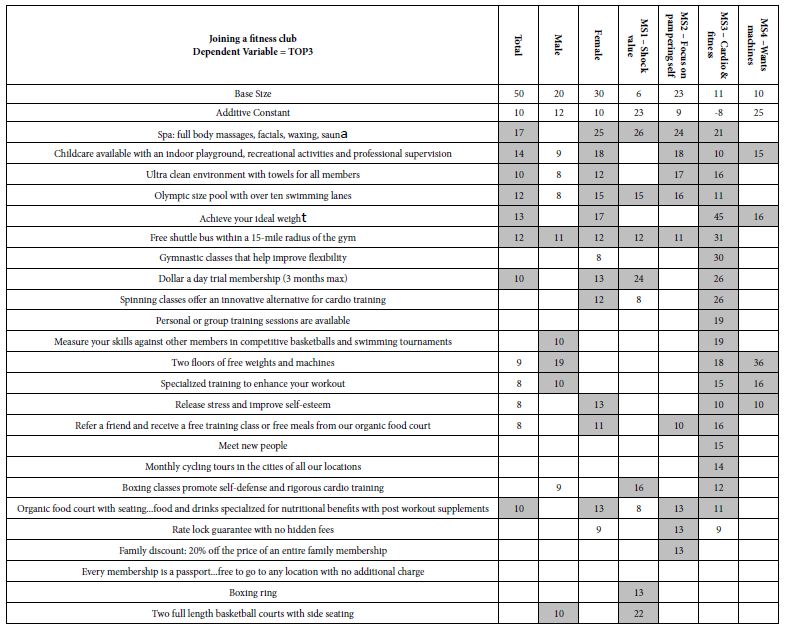
The most predominant biological functions associated with mycotoxin exposure were regulation of kinase activity and cellular response to growth factor stimuli. The most predominant molecular functions were receptor of signaling protein serine/threonine kinase activity and MAP kinase activity (Table 1). Table 1 showed that the most predominant molecular functions were receptor signaling protein serine/threonine kinase activity and MAP kinase activity. Identification of gene ontology (GO) annotation was performed by Reactome, and illustrated by STRING protein interaction software.
Table 1: Gene ontology annotation of major biological and molecular functions associated with proteins phosphorylated or dephosphorylated in theca cells by mycotoxin exposure.
| Pathway description |
Count in gene set |
False discovery rate |
| Biological function:
Regulation of kinase activity |
8 |
0.00178 |
| Regulation of cellular response to heat |
4 |
0.00253 |
|
Protein folding |
5 |
0.00269 |
| Cellular response to growth factor stimulus |
7 |
0.00269 |
| Regulation of protein kinase activity |
7 |
0.00295 |
| Molecular function:
Receptor signaling protein serine/threonine kinase activity |
5 |
1.13e-05 |
| MAP kinase activity |
3 |
0.000311 |
Significance was calculated within SIEVE using a standard t-test. Statistical significance was set at a P value < 0.05.
Network analysis with STRING shows the active interactions between these signaling molecules in the form of nodes and edges (Figure 3). In this model, network nodes represent proteins and each node represents all the proteins produced by a single, protein-coding gene locus. Small nodes illustrate protein of unknown 3D structure and the large nodes illustrate proteins of known (or predicted) 3D structure. The green nodes represent the proteins whose phosphorylation was upregulated in response to DON and DOM-1 and the red nodes represent proteins whose phosphorylation was downregulated in response to these mycotoxins. The edges represent the protein-protein associations. The blue edges represent associated from curated database and is a characteristic of gene co-occurrence. The violet edges identify genes that are homologous and are co-expressed. This STRING network shows a clear cluster of known or predicted interactions between MAPK1, MAPK13, MAPK14, EDN1, GNGT1 and YWHAB, which were hyperphosphorylated in response to DON and DOM-1.
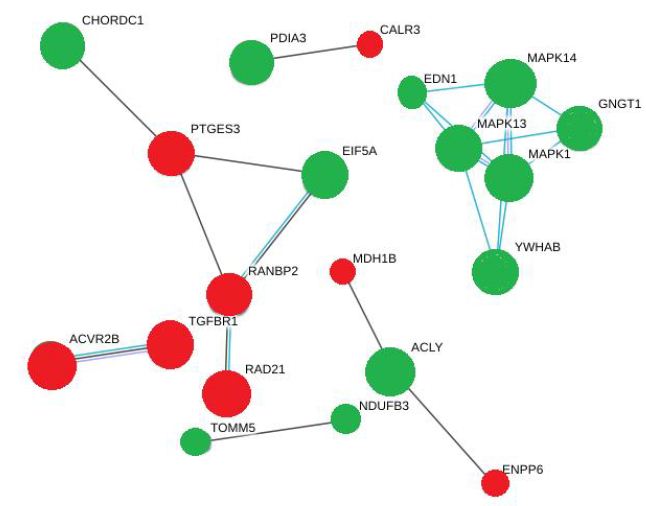
Figure 3: A string model of different intracellular signaling pathways activated by DON and DOM-1. MAPKs are the core signaling molecules in this network green and red nodes indicate upregulated and downregulated molecules respectively. The edges are also representative of various interactions.
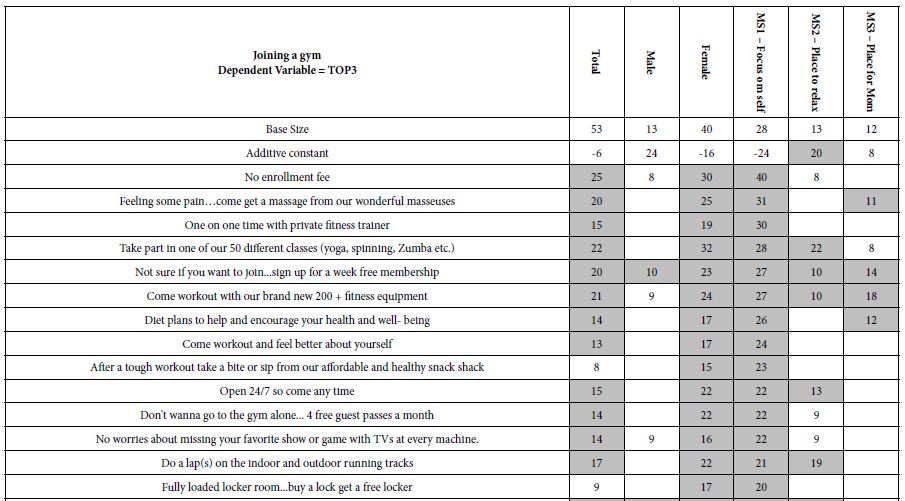
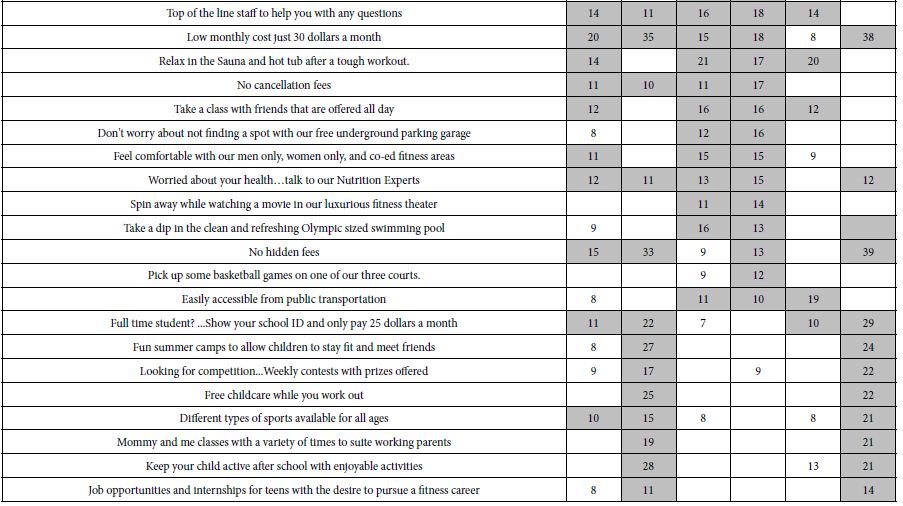
There was another cluster of interactions between PTGES3 and CHORDC1, EIF5A and RANBP2, involving hyperphosphorylation of CHORDC1 and EIF5A but hypophosphorylation of PTGES3 and RANBP2. Based on the statistical importance of these interactions, the proteins with increased phosphorylation and their functions are listed in Table 2. This Table showed that Both DON and DOM-1 induce simultaneous upregulation of ERK1/2, MAPK14 (p38alpha), MAPK13 (p38delta), GNGT1, EDN1 and YWHAB. They mostly regulate cell proliferation pathways and are involved in biosynthesis of lipid and carbohydrates (>2-fold; P<0.01). Table 3 demonstrated the differential proteomic analysis of hypophosphorylated proteins in response to DON and DOM-1 in bovine ovarian theca cells. Both DON and DOM-1 induce simultaneous downregulation of CALR3, PTGES3, RAD21, ACVR2B, and TGFBR1. They mainly activate or deactivate apoptotic processes and are involved in glucose and choline metabolism (>2-fold; P<0.01).
Table 2: Up-regulated phosphorylated Proteins of bovine ovarian theca cells in response to DON and DOM-1.
|
Protein name |
Peptide Sequence | Fold increase by DON | Fold increase by DOM-1 |
Function |
| MYCBP | TKLAQYEPPQEEKR |
12 |
7 |
Stimulates activation of E-box-dependent transcription by MYC, a proto-oncogen protein |
| CALML4 | YDEFIQKLTIPVRDY |
12 |
9 |
Ca+2 ion binding protein, correlates with MYO5A, B and 1G, involves in cell malignancy |
| LAMTOR4 | MTSALTQGLER |
5 |
5 |
An amino acid sensing molecule and activator of TORC1 family members, which are carcinogens, promotes cell growth in response to growth factors |
| CXCL11 | TEVIITLK |
4 |
4 |
A chemotactic for interleukin-activated T-cells, involves in tumor angiogenesis |
| MAPK1 | VADPDHDHTGFLTEYVATR |
2.4 |
2.2 |
Main component of Ras/Raf/MEK/ERK cascade, mediates cell growth and survival, participates also in a signaling cascade initiated by activated KIT and KITLG/SCF. |
| MAPK14 | HTDDEMTGYVATR |
5.1 |
6.5 |
One of the four p38 MAPKs, cellular response to pro-inflammatory cytokines and physical stress |
| MAPK13 | HTDVEMTGYVVTR
|
7.7
|
4.9
|
MAPK activity, one of the four p38 MAPKs, cellular response to pro-inflammatory cytokines and physical stress, activation of transcription factors such as ELK1 and ATF2 |
| GNGT1 | MPVINIEDLTEKDKLK |
2.1 |
2.2 |
Signal-transducer activity, GTPase activity |
| EDN1 | LKAQLYRDK
|
2.8 |
3.1 |
Positive regulation of mitotic nuclear division, protein kinase C-activating G-protein coupled receptor signaling pathway |
| YWHAB | VFYLKMKGDYFR
|
4.7 |
5.8 |
Blocks the nuclear translocation of the phosphorylated form (by AKT1) of SRPK2 and antagonizes its stimulatory effect on cyclin D1 |
| CHORDC1 | SYVTMTATKIEITMRK |
3.1 |
2.3 |
Involved in stress response, regulates centrosome duplication, acts as co-chaperone for HSP90 |
| TOMM5 | EDVISSIR
|
2.1 |
1.7 |
Mitochondrial outer membrane translocase complex, responsible for the degradation of active cytoplasmic enzyme and organelles during nutrient starvation |
| EIF5A | IVEMSTSKTGK |
2.2 |
2.3 |
mRNA-binding protein involves in translation elongation, regulates also TNF-alpha-mediated apoptosis |
| NDUFB3 | DPWGRNEAWRYMGGFANNVSFVGALLK |
2.5 |
2.9 |
Electron transform from NADH to the respiratory chain (ubiquitin), integral component of the membrane |
| ACLY | SGASLKLTLLNPKGR
|
2.8 |
2.1 |
Acetyl-CoA biosynthetic process, citrate metabolic process, lipid biosynthetic process |
| PDIA3 | GFPTIYFSPANKKQNPK
|
2.8 |
3.1 |
Catalyzes the rearrangement of -S-S- bonds in proteins, responds to endoplasmic reticulum stress |
Significance was calculated within SIEVE using a standard t-test. Statistical significance was set at a P value < 0.05.
Table 3: Down-regulated phosphorylated Proteins of bovine ovarian theca cells in response to DON and DOM1.
|
Protein name |
Peptide Sequence | Fold decrease by DON | Fold decrease by DOM-1 |
Function |
| THEM4 | SIWALRGR |
-33 |
-33 |
A thioestrase that involves in mitochondrial fatty acid metabolism |
| PDP1 | LRPQDKFLVLATDGLWETMHR |
-22 |
-22 |
Catalyzes the dephosphorylation of the α-subunit of the E1 component of the pyruvate dehydrogenase complex |
| ST6GAL2 | GEDGERLYSSMSRALLR |
-20 |
-20 |
Transfers sialic acid from the substrate CMP-sialic acid to galactose containing acceptor substrates from oligosaccharides |
| PPARG | LNHPESSQLFAKLLQKMTDLR |
-10 |
-16 |
Regulates β-oxidation of fatty acids, negative regulator of cholesterol storage |
| HNRNPA1 | VVEPKRAVSR |
-7 |
-7 |
Packaging of pre-mRNA into hnRNP particles, transports poly (A) mRNA from nucleous to the cytoplasm |
| CALR3 | GKTLIIQYTVKHEQK |
-7.1 |
-7.7 |
Ca+2 binding, cell differentiation |
| PTGES3 | SILCCK |
-5.6 |
-6.7 |
Cell proliferation, PGE synthase activity |
| MDH1B | ELEKESLK |
-5.6 |
-2.7 |
TCA cycle, malate dehydrogense activity |
| RAD21 | KLIVDSVKELDSK |
-5.0 |
-6.3 |
Apoptotic process, cell division, RNA polymerase II transcription regulatory, region sequence-specific binding |
| ENPP6 | HSEIYNKVRR |
-5.0 |
-5.3 |
Phosphodiesterase activity, choline metabolic process, lipid catabolic process |
| RANBP2 | SGLKDFKTFLTNDQTK |
-5.0 |
-5.3 |
Regulation of gluconeogenesis, involved in cellular glucose homeostasis, ligase activity |
| ACVR2B | SVNGGTDCLVSLVTSVTNDLPK |
-4.0 |
-6.7 |
ATP binding, metal ion binding, receptor signaling protein Ser/Thr kinase activity |
| TGFBR1 | IELPTVGKPSSGLGPVLAVEEAGPVCFVCISLAMVAC |
-2.4 |
-4.8 |
A receptor signaling protein with ser/thr kinase, activity, transforming growth factor beta binding, activation of MAPKK activity, pathway-restricted SMAD protein phosphorylation, positive regulator of apoptosis |
Significance was calculated within SIEVE using a standard t-test. Statistical significance was set at a P value < 0.05.
Discussion
Analysis of biological processes and functions indicated that 30 min exposure to DON or DOM-1 activated MAPK activity and growth factor signaling pathways in the bovine theca cells. This is consistent with the known ability of DON to rapidly increase phosphorylation of MAPK3/1, and demonstrated in numerous cell type including granulosa cells [22].
According to an in vitro study, human and porcine lymphocytes responded differently when they were exposed to DON, in which exposure to low doses (30 nM) and high doses (100 nM) for 24h activated and suppressed mitogen induced proliferation of lymphocytes respectively [23]. In another study, the in vitro exposure of the porcine lymphocytes to low doses of DON (less than 10 ng/mL) stimulated immune system function by upregulation of cytokines, chemokines and inflammatory genes expression whereas at high doses (100 to 250 ng/mL ) DON suppressed immune system by activating apoptotic pathways [24].
Our result showed that three of the most significantly increased phosphoproteins were MAPK1, MAPK3 and, MAPK14. MAPK1 (also known as ERK2) is a Ser/Thr kinase which is phosphorylated by MAP2K1/MEK1 and MAP2K2/MEK2 on thr-185 and tyr-187 in response to external stimuli, and mediates many biological functions such as cell growth, survival, differentiation and apoptosis [25]. This protein is a critical component of the Ras-Raf-MEK-ERK signal transduction cascade. The ERK cascade is highly upregulated in human cancers, and is typically activated by growth factor stimulation of cell surface receptor tyrosine kinases (RTKs) and other signaling molecules with known oncogenic potential [26]. Reactome analysis suggested significant association of the MAPKs with endothelin 1 (EDN1) which is an endothelium-derived vasoconstrictor peptide. EDN1 has 2 receptors, EDNRA and EDNRB, that subsequently activate G proteins-coupled receptors [27] However, EDNRA also activates Ras-Raf-MEK-ERK signaling pathway and the upstream signaling molecules [28]. EDN1 receptors initiate intracellular signaling pathways leading to activation of MAPK3/1, MAPK14 and JNK1 [29]. In cattle the EDNR was identified in luteal, granulosa and thecal cells, and the luteal EDNRA and EDNRB mRNA levels were increased between day 1 and 10 of the estrous cycle. Moreover, the expression of EDNRA was greater in bovine theca cells than granulosa cells [30]. In contrast, follicular EDNRA and EDNRB mRNA decrease in super-ovulated cows treated with GnRH [31]. The phosphorylation of EDN1 by DON and DOM-1 treatment may account at least in part to the contribution of EDN1 in stimulating folliculogenesis. The YWHAB, also known as a 14-3-3 protein β, has a role in the Ras-signal transduction pathway and is a positive regulator of MAPK activity. It blocks the nuclear translocation of AKT1 and antagonizes the stimulatory effect of AKT on cyclin D1 expression, and eventually blocks apoptosis [32]. If indeed EDN1 and YWHAB are upstream of MAPK activity, these data suggest that DON and DOM-1 may act through these pathways. The increase in phosphorylation of these proteins in response to the DON and DOM-1, may be an initial protective response of the cells to these agents, however, there is no clear evidence for interactions between these molecules and DON. Some signaling molecules were dephosphorylated after addition of DON and DOM-1, including molecules such as transforming growth factor-β receptor type 1 (TGFBR1). This molecule is a potent inhibitor of epithelial and hematopoietic cell growth and proliferation [33]. The dephosphorylation of this protein is inconsistent with the simultaneous increase in MAPK phosphorylation observed after DON and DOM-1 treatment, although it is likely that the timing of changes of these proteins phosphorylation is not the same as the MAPKs [34]. Decreased phosphorylation of this molecule would be expected to favor proliferative pathways, which is inconsistent with the actions of DON and DOM-1 on theca cells in higher doses. A detailed time-course may also allow the determination of the sequence of intracellular pathway activation in response to DON and DOM-1.
The bottom-up mass spectrometry approach used in this study is however limited by the phosphor-enrichment strategy. The enrichment chemistry is not infallible, and it is likely that some phospho-peptides are not efficiently retained on the titanium solid phase. An alternative approach would be to separate proteins on SDS gel and perform in-gel tryptic digestion of narrow molecular mass bands containing proteins of interest. For example, MAPK1, MAPK3 and MAPK14 are between 38 and 44 kDa in size and could be easily isolated and examined without phospho-enrichment. The functional biology of the putative interactions of MAPK, EDN1, GNGT1 and YWHAB warrant exploration. Initial experiments would include the use of MAPK inhibitors to determine if MAPK activation is necessary for DON-induced changes in EDN1, GNGT1 and/or YWHAB phosphorylation.
Conclusion
This study has revealed that exposure of theca cells to low (sub-toxic) doses of DON and DOM-1 results in increased activation of several major MAPK signaling pathways similar to that of immune system cells. We concluded that both DON and DOM-1 have the potential to upregulate distinct MAPKs and downregulate specific signaling pathways that eventually stimulate bovine ovarian theca cell proliferation.
Acknowledgements
This research work was supported by NSERC Canada. We would like to thank Thermo Fisher Scientific for providing access to a Q-Exactive Quadrupole-Orbitrap Mass Spectrometer.
Supplementary Information Legends
Supplementary Table S1: The list of phosphorylated peptides in DON and DOM-1 vs. control group.
Supplementary Table S2: The list of dephosphorylated peptides in DON and DOM-1 vs. control group.
References
- Nani JP, Rezende FM, Peñagaricano FJ (2019) Predicting male fertility in dairy cattle using markers with large effect and functional annotation data. BMC Genomics 20: 258-259.
- Liu H, Liu Z, Meng L, et al. (2019) Toxic effects of 1-(N-methyl-N-nitrosamino)-1-(3-pyridinyl)-4-butanal on the reproduction of female mice. Ecotoxicology and Environmental Safety 181: 370-380. [crossref]
- Darwish AJMB (2019) Fungal mycotoxins and natural antioxidants: Two sides of the same coin and significance in food safety. Microbial Biosystems 4: 1-16.
- Kos J, Hajnal EJ, Šarić B, et al. (2017) The influence of climate conditions on the occurrence of deoxynivalenol in maize harvested in Serbia during. Food Control 73: 734-740. [crossref]
- Pestka JJ (2010) Deoxynivalenol: mechanisms of action, human exposure, and toxicological relevance. Archives of Toxicology 84: 663-679. [crossref]
- De Loubresse NG, Prokhorova I, Holtkamp W, et al. (2014) Structural basis for the inhibition of the eukaryotic ribosome. Nature 513: 517-522. [crossref]
- Pierron A, Mimoun S, Murate LS, et al. (2016) Microbial biotransformation of DON: molecular basis for reduced toxicity. Scientific Report 6:1-3. [crossref]
- Bertero A, Moretti A, Spicer LJ, et al. (2018) Fusarium molds and mycotoxins: Potential species-specific effects. Toxins 10: 244-245. [crossref]
- Young J, McNeilly AS (2010) Theca: the forgotten cell of the ovarian follicle. Reproduction 140: 489-490. [crossref]
- Spicer LJ, Aad PY, Allen DT, et al. (2008) Growth differentiation factor 9 (GDF9) stimulates proliferation and inhibits steroidogenesis by bovine theca cells: influence of follicle size on responses to GDF9. Biol Reprod 78: 243-253. [crossref]
- Kim H, Cho S, Choe C, et al. (2006) Effect of concentration and exposure duration of fetal bovine serum on parthenogenetic development of porcine follicular oocytes. Reproduction, Fertility and Development 19: 208-209.
- Allegrucci C, Hunter M, Webb R, et al. (2003) Interaction of bovine granulosa and theca cells in a novel serum-free co-culture system. Reproduction-Cambridge 126: 527-538. [crossref]
- ŞİMŞEK Ö, Mihm M (2014) Activity of 3\beta-hydroxysteroid dehydrogenase associated with progesterone production in bovine granulosa cells cultured under different concentrations of serum, insulin-like growth factor I, and gonadotropin. Turkish J Vet and Anim Scie 38: 358-362.
- You M, Matsumoto M, Pacold CM, et al. (2004) The role of AMP-activated protein kinase in the action of ethanol in the liver. Gastroenterology 127: 1798-1808.
- Ma J, Hart GW (2017) Analysis of Protein O-GlcNAcylation by Mass Spectrometry. Current Protocols in Protein Science 87: 24-10. [crossref]
- Tóth G, Bugyi F, Sugár S, et al. (2020) Selective TiO2 Phosphopeptide Enrichment of Complex Samples in the Nanogram Range. Separations 7: 74-75.
- Aminmarashi F, Torabi A, Beaudry F (2018) Effects of fibroblast growth factor 8 and 18 on ovine ovarian granulosa cell function. Int J Reprod Biomed 17: 435-442.
- Biau DJ, Kernéis S, Porcher R (2008) Statistics in brief: the importance of sample size in the planning and interpretation of medical research. Clin Orthop Relat Res 466: 2282-2288. [crossref]
- Ferreira D, Santarosa B, Monteiro-Toma C, et al. (2013) Anatomorphological, radiographic and tomographic studies of Schistosomus reflexus in Dorper breed sheep: case report. Arq Bras Med Vet Zootec 65: 1096-1102.
- Fabregat A, Sidiropoulos K, Garapati P, et al. (2015) The reactome pathway knowledgebase. Nucleic Acids Research 44: 481-487.
- Chang D, Nalls MA, Hallgrímsdóttir IB, et al. (2017) A meta-analysis of genome-wide association studies identifies 17 new Parkinson’s disease risk loci. Nature Genetics 49: 1511-1516. [crossref]
- Pestka JJ (2007) Deoxynivalenol: toxicity, mechanisms and animal health risks. Animal Feed Science and Technology 137: 283-298.
- Taranu I, Marin DE, Burlacu R, et al. (2010) Comparative aspects of in vitro proliferation of human and porcine lymphocytes exposed to mycotoxins. Arch Anim Nutr 64: 383-393. [crossref]
- Pestka JJ (2008) Mechanisms of deoxynivalenol-induced gene expression and apoptosis. Food Addit Contam 25: 1128-1140. [crossref]
- Kyriakis JM, Avruch JJ (2012) Mammalian MAPK signal transduction pathways activated by stress and inflammation: a 10-year update. Physiological Reviews 92: 689-737. [crossref]
- Pritchard AL, Hayward NKJCCR (2013) Molecular pathways: mitogen-activated protein kinase pathway mutations and drug resistance. Clinical Cancer Research 19: 2301-2309. [crossref]
- Minchenko DO, Tsymbal DO, Riabovol OO, et al. (2019) Hypoxic regulation of EDN1, EDNRA, EDNRB, and ECE1 gene expressions in ERN1 knockdown U87 glioma cells. Endocr Regul 53: 250-262. [crossref]
- Lee HJ, Wall B, Chen S (2008) G‐protein‐coupled receptors and melanoma. Pigment Cell & Melanoma Research 21: 415-428. [crossref]
- Stow LR, Jacobs ME, Wingo CS, et al. (2011) Endothelin-1 gene regulation. J FACEB 25: 16-28. [crossref]
- Ervin J, Schütz L, Spicer L (2017) Current status of the role of endothelins in regulating ovarian follicular function: a review. Anim Reprod Sci 186: 1-10. [crossref]
- Takagi M, Yamamoto D, Ogawa S, et al. (2008) Messenger RNA expression of angiotensin-converting enzyme, endothelin, cyclooxygenase-2 and prostaglandin synthases in bovine placentomes during gestation and the postpartum period. J Veterinary 177: 398-404. [crossref]
- Zheng P, Zhong Q, Xiong Q, et al (2012) QUICK identification and SPR validation of signal transducers and activators of transcription 3 (Stat3) interacting proteins. J Proteom 75: 1055-1066.
- Zhang J-Q, Gao B-W, Guo H-X, et al. (2020) miR-181a promotes porcine granulosa cell apoptosis by targeting TGFBR1 via the activin signaling pathway. Mol Cell Endocrinol 499: 110-115. [crossref]
- Shav-Tal Y, Lapter S, Parameswaran R, et al. (2001) Activin receptors: Cytokine Reference (Online book edition). Academic Press 283: 113-118.